Introduction
基于 Prompt(模版)增强的微调范式在少样本学习等场景下可以有效提升下游任务上的效果,Prompt最初诞生于GPT系列的自回归预训练语言模型,GPT 模型在零样本场景下的运行方式是:基于一定的任务描述(task description),按这一描述的指定生成文本: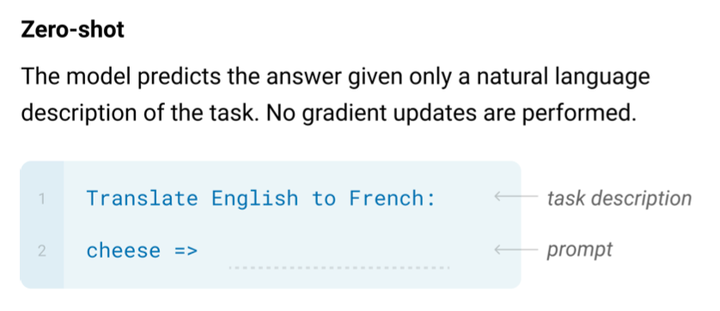
仅仅几个单词组成的任务描述,就可以为语言模型的预测提供指导,这启发了一些少样本领域的工作——在缺少训练数据的场景下,利用任务描述能很好地提升模型的效果。
另一个灵感来自预训练语言模型的 Masked Language Model/MLM 任务:在 BERT 的训练中,有 15% 的输入词被选中,其中的绝大部分又被替换为 [MASK] 标签或者随机的其他词,并在最终的 hidden states 中对被遮盖的词进行预测,通过还原遮盖词让模型学习单词级别的上下文信息。
将这两个灵感融合,就得到了以下将介绍的 Pattern-Exploiting Training,或 PET 方法。
Related Work
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
PET 来自 2020 年的论文(已发表在 EACL 2021)《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》,其中介绍了一种基于模版和词遮盖将文本分类任务转换为完形填空(cloze)任务的半监督训练方法,仅使用 RoBERTa-base 模型就在多个半监督场景下取得了 SOTA: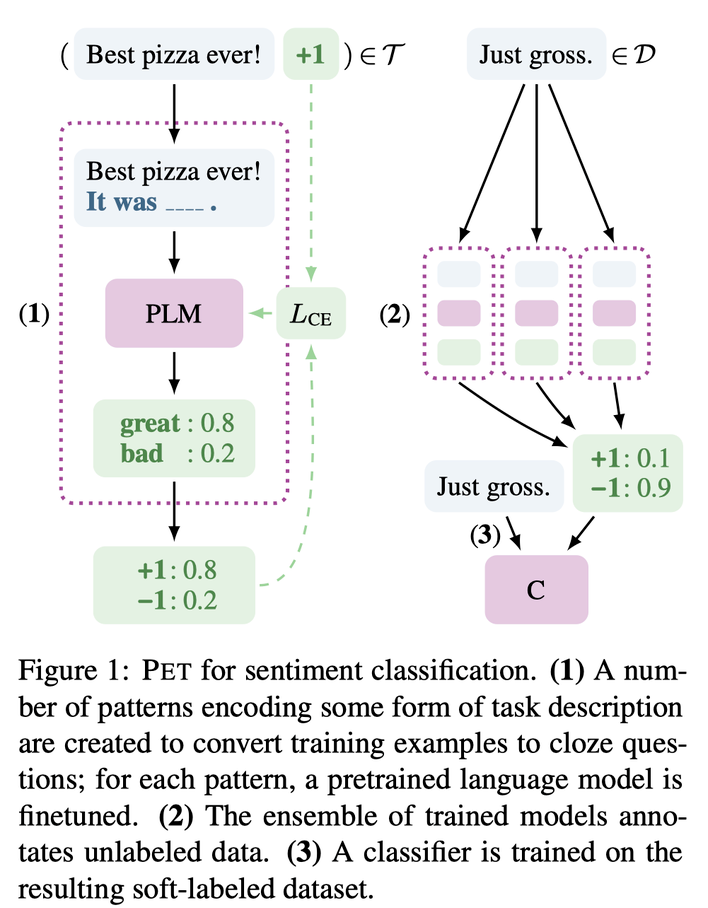
首先,针对少量样本设计描述的模版(pattern),如上图中对 “Best pizza ever!” 的情感分类任务,生成一个 “It was ___” 的句子并拼接在原始输入后作为补充;
- 对模版中遮盖的词(即下划线部分),设计候选词对应不同的情感极性(图中 great 对应 positive,bad 对应 negative),然后将模型预测 “great” 的概率作为原来预测 “positive” 的概率,从而将情感分类任务转换为完形填空任务。
- 当然,原文中对 NLI 任务也进行了模版构建,其操作有所不同,在此不展开;
- 注意,完形填空和 MLM 不是一个任务,虽然二者都是词分类任务,但是类别一个是候选词集,一个是模型中全部的词集;
对有标签样本集设计不同的模版,然后对每一个模版,分别训练模型;
- 因为有标签样本比较少,所以训练成本低于全量数据训练一个完整的模型;
- 这里的训练因为是有监督的,所以结合了完形填空的词分类 loss 和 MLM Loss 进行训练:$L=(1-\alpha) \cdot L_{\mathrm{CE}}+\alpha \cdot L_{\mathrm{MLM}}$,其中 MLM loss 占较小比重(1e-4);
使用上面训练得到的一堆模型,在无标签数据上进行预测,按不同 pattern 的模型 acc 对应权重对所有的预测进行归一化,作为 soft label 蒸馏一个最终模型;
- 这里最终模型并不进行 pattern 的学习;
- 在这里的训练中,不涉及 MLM loss。
在 PET 的基础上,为了让不同模版训练出的模型互相学习,文中还提出了一种迭代式的 PET 训练(Iterative PET,iPET):
- 其实就是进行多代交叉的蒸馏,随机选取每一代的模型为无标签数据进行标记,并基于此进一步训练下一代模型;
- 最终和 PET 一样,用不同模型标注的无标签数据进行预测,蒸馏一个统一的模型。
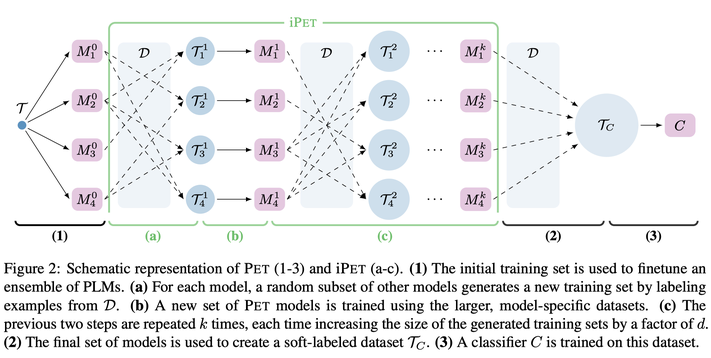
说完了训练过程,我们看看这里的模版(pattern):
- 情感分类(Yelp):

- 文本蕴含(MNLI):

可以看出,人工构建的模板比较简单,语义上也和任务具有较好的关联。
在这一半监督场景工作的基础上,本文作者进一步在 NAACL 2021 上发表了《It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》,通过将小模型(ALBERT)和 GPT-3 这一巨无霸在 SuperGLUE benchmark 上进行对比,进一步挖掘 PET 训练在少样本场景下的潜力。由于使用的基本是同一个方法(补充了实际训练中 multi-token 的 mask 预测),所以不再重复,在此贴出论文的实验结果: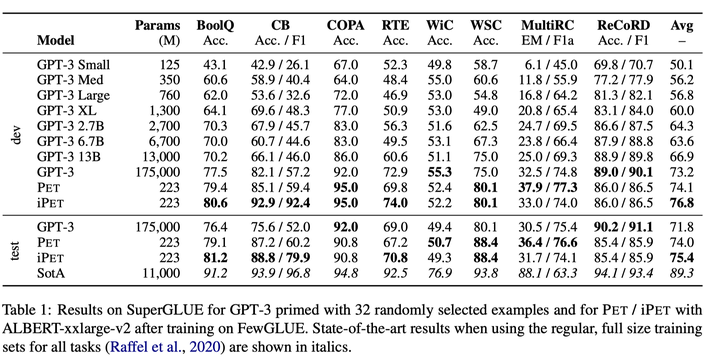
_中文实验_
自动构建Prompt
人工构建 pattern/prompt 就像在进行手工的特征工程,对输入特征进行人工的选择和组合,手工选取模版的方法自然会被自动选取特征的方法取代:
LM Prompt And Query Archive
最早提出自动构建模版的工作应该是发表在 TACL 2020 的《How Can We Know What Language Models Know?》,其中提出了一个 LPAQA(LM Prompt And Query Archive)方法以进行模版的自动搜索。
具体而言,LPAQA 包含两部分生成方法:
Mining-based Generation:基于远程监督的假设(即,出现相同实体对的句子表达相同的关系),在 Wikipedia sentence 中寻找包含头尾实体 h、t 的句子,然后进一步提出了两种 prompt 抽取方法:
- Middle-word Prompts:对于 h、t 中间包含文本的句子形式,将 h、t 中间的文本当作 prompt;
- Dependency-based Prompts:对于其他句子,使用句法依赖解析来提取 h 和 t 最短的路径,并将路径上的词作为 prompt。
Paraphrasing-based Generation:类似查询拓展技术,在保持原 prompt 语义同时增加词汇的多样性。这种方法依赖反向翻译(back-translation),即翻译到另一种语言再翻译回来,构成多个样本后根据往返概率(round-trip probability)筛选 prompt。
显然,第一种方法会引入噪音,而第二种也具有不稳定性。因此,需要进一步筛选高质量的生成语句,为此本文提出了 selection 和 ensemble 的方法:
- Top-1 Prompt Selection:就是用 LM 测一测看看效果,取 acc 最高的 prompt;
- Rank-based Ensemble:除了 Top-1 方案,有时候需要保持多个模版来增强效果,即选取前 K 个模版;
- Optimized Ensemble:通过 LM 的预测为不同的 prompt 赋权。
AUTOPROMPT
这是来自 EMNLP 2020 的文章《AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts》,提出了一种基于梯度的模版搜索方案,如下图: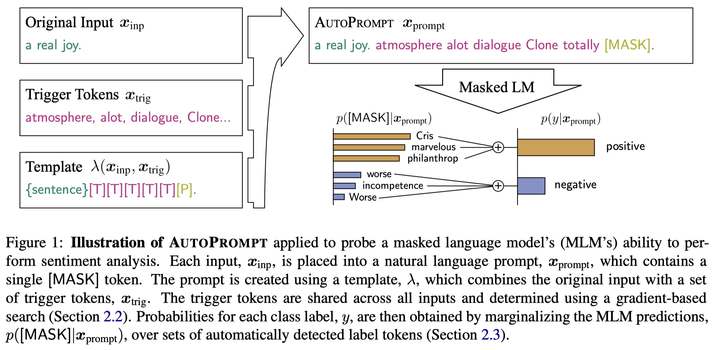
AutoPrompt根据模板$\lambda$,将原始任务输入$x$与一系列触发令牌$x_{trig}$相结合,构建一个提示符。注意触发器令牌在所有输入中共享,因此普遍有效。
AutoPrompt使用梯度搜索机制来寻找触发词$x_{trig}$,本质上是计算监督损失的一阶导数:$$
e_{\mathrm{trig}}^{(t+1)}=\arg \min _{e \in \mathcal{V}}\left[e-e_{\mathrm{trig}}^{(t)}\right]^{\top} \nabla_{e_{\mathrm{trig}}^{(t)}} \mathcal{L}
$$
类似于计算扰动然后找knn近邻。示意图如下: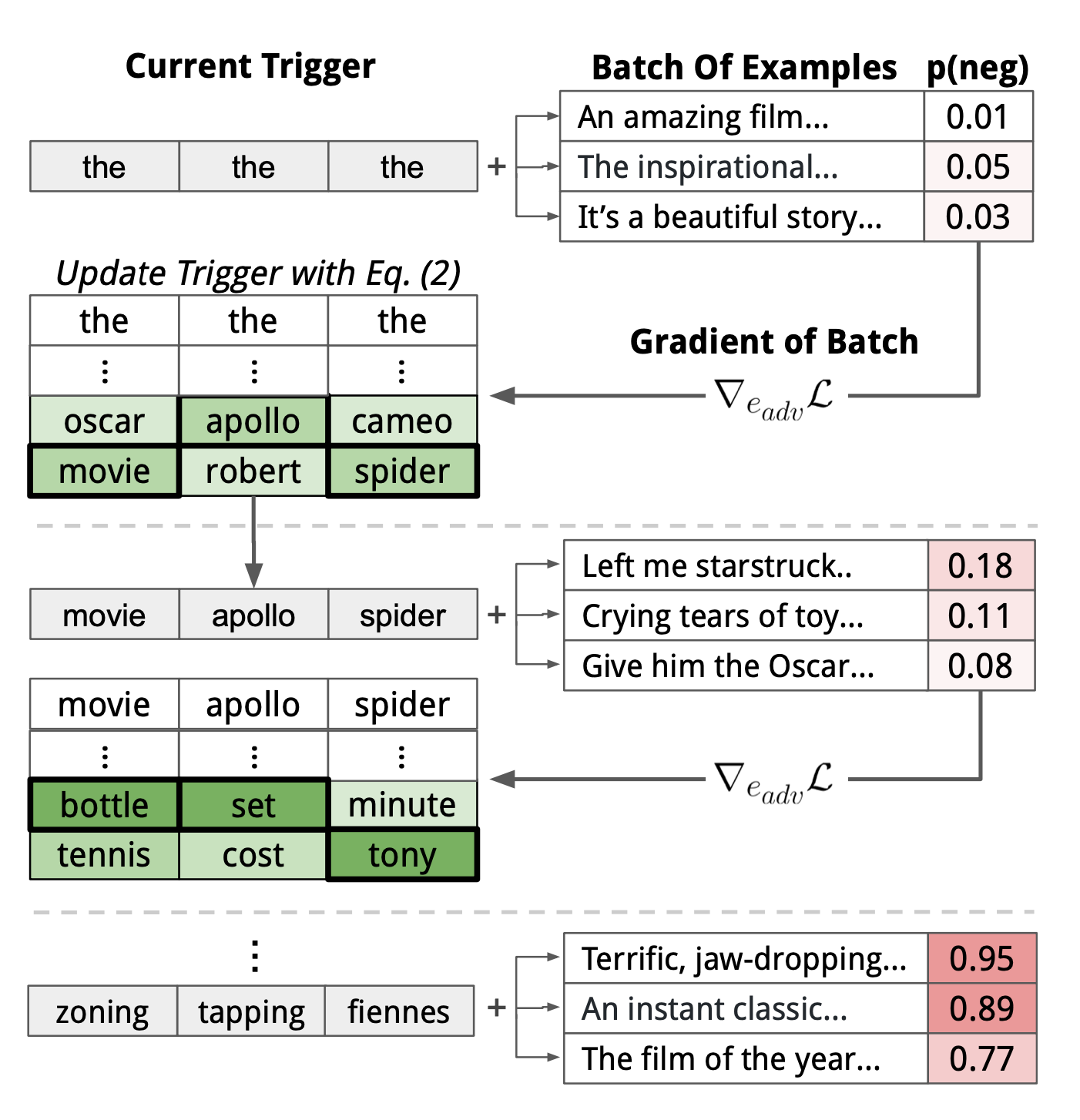
生成prompt之后,通过[MASK]来预测下游任务。这里作者做了一些简化:对于由词表中的词生成的标签,直接通过[MASK]预测;而对于类似positive/negative这种二分类任务,作者首先通过一个二分类模型预测每个类别对应的类别词,然后对类别下所有类别词的生成概率进行求和,作为最终的预测概率。
$$
p\left(y \mid \boldsymbol{x}_{\text {prompt }}\right)=\sum_{w \in \mathcal{V}_{y}} p\left([\mathrm{MASK}]=w \mid \boldsymbol{x}_{\text {prompt }}\right)
$$
实验结果:
Better Few-shot Fine-tuning of Language Models
这一工作来自 Danqi Chen 大佬的小组:《Making Pre-trained Language Models Better Few-shot Learners》,探究少样本场景下 Prompt 的作用,基于谷歌的 T5 模型构建了一个自动化的 pipeline: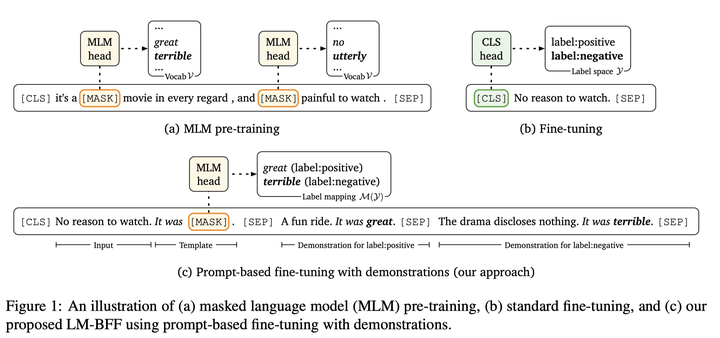
同样注意到 PET 方法的低效,这一工作提出了一种名为 LM-BFF 的架构,引入了T5(Text-to-Text Transfer Transformer)生成模型用于自动化生成 Prompt;此外还加入了 demonstrations(示例)与 prompt 一并输入以为预测提供指导。这一灵感来自于 GPT 在少样本场景的工作方式,即将示例样本与任务描述一并输入模型:
LM-BFF包含两个方面,一是自动搜索标签词和模板,一是自适应引入Demonstration。
对于自动标签词搜索,目标是找到一组可以最大化验证集上性能的标签词,给定一个人工模板,一种简单的方法是暴力搜索所有单词组合。但这样不太可行,因为搜索空间是类数量的指数级别,并且该方法容易导致伪相关和过拟合。我们的做法是,首先为每个类 构建一个候选词集 :用 表示类 的所有训练样本,给定模板和 ,我们找到能最大化的 [MASK] 处的 LM 概率的top-k个词。然后我们枚举 的所有单词组合,并找到最大化训练集上的零样本准确率的 top-n 组合。最后,我们对所有 n 个组合进行微调,并根据验证集上的表现对它们重排序(rerank)。我们发现剪枝空间中的暴力搜索和微调重排序对于提升最终性能都很有帮助。
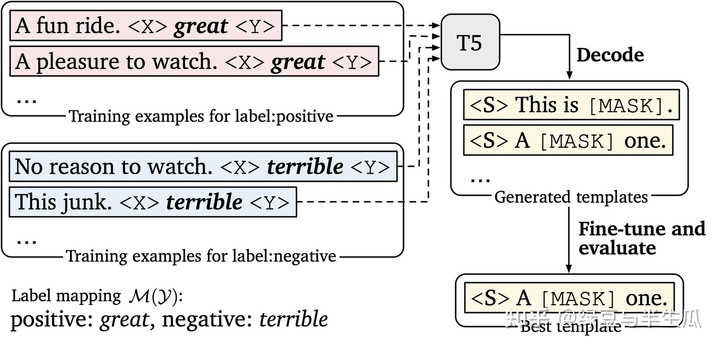
对于自动模板搜索,目标是相似的:在给定人工标签词的情况下,找到使验证集上准确率最高的模板。我们使用T5,开箱即用,生成了许多候选模板,然后通过验证集表现对它们进行rerank。T5 是一个 seq-to-seq 模型,使用完形填空的目标进行了预训练,非常适合用来生成模板。以情感分类(上图)为例,我们将输入样本和对应的标签词连接起来,并在标签词周围插入
引入Demonstration:前文已经介绍了 GPT-3 如何在上下文中使用demonstration:从训练集中随机抽样并以任意顺序连接它们,这样其实在很多方面都会有问题:预训练的 LM 的输入长度是有限的,尤其是对于较小的(通常是512)来说;如果样本以随机顺序连接,则很难得到有意义的pattern;与输入实例相差太大的demonstration可能会没有帮助,甚至会引起混淆。因此,我们提出了一种动态地、有选择地方式来引入demonstration:
- 在训练和推理期间,我们从训练集中为每个类随机抽取一个样本并将它们连接起来。对于推理,我们对抽取多组demonstration,并在最后对结果进行集成。
- 我们只采样与输入密切相关的demonstration。例如,如果输入是电影评论,就对电影评论进行采样,而不是餐厅评论。我们采用 SBERT ( Reimers and Gurevych, 2019 ) 对句子进行编码,计算输入与训练集中所有样本之间的余弦相似度,然后仅从前 50% 的样本中进行采样。
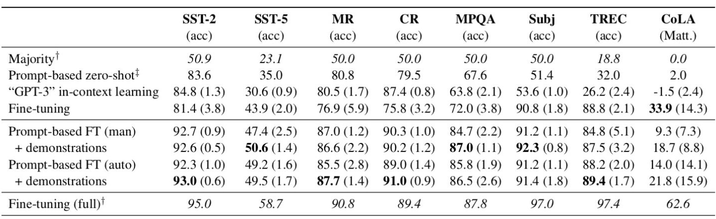
实验结果如下:
- 可以看出 prompt FT(auto) + demonstrations > prompt FT(auto) > prompt FT(man) > FT;
- 但是全量数据 FT 还是比不过。
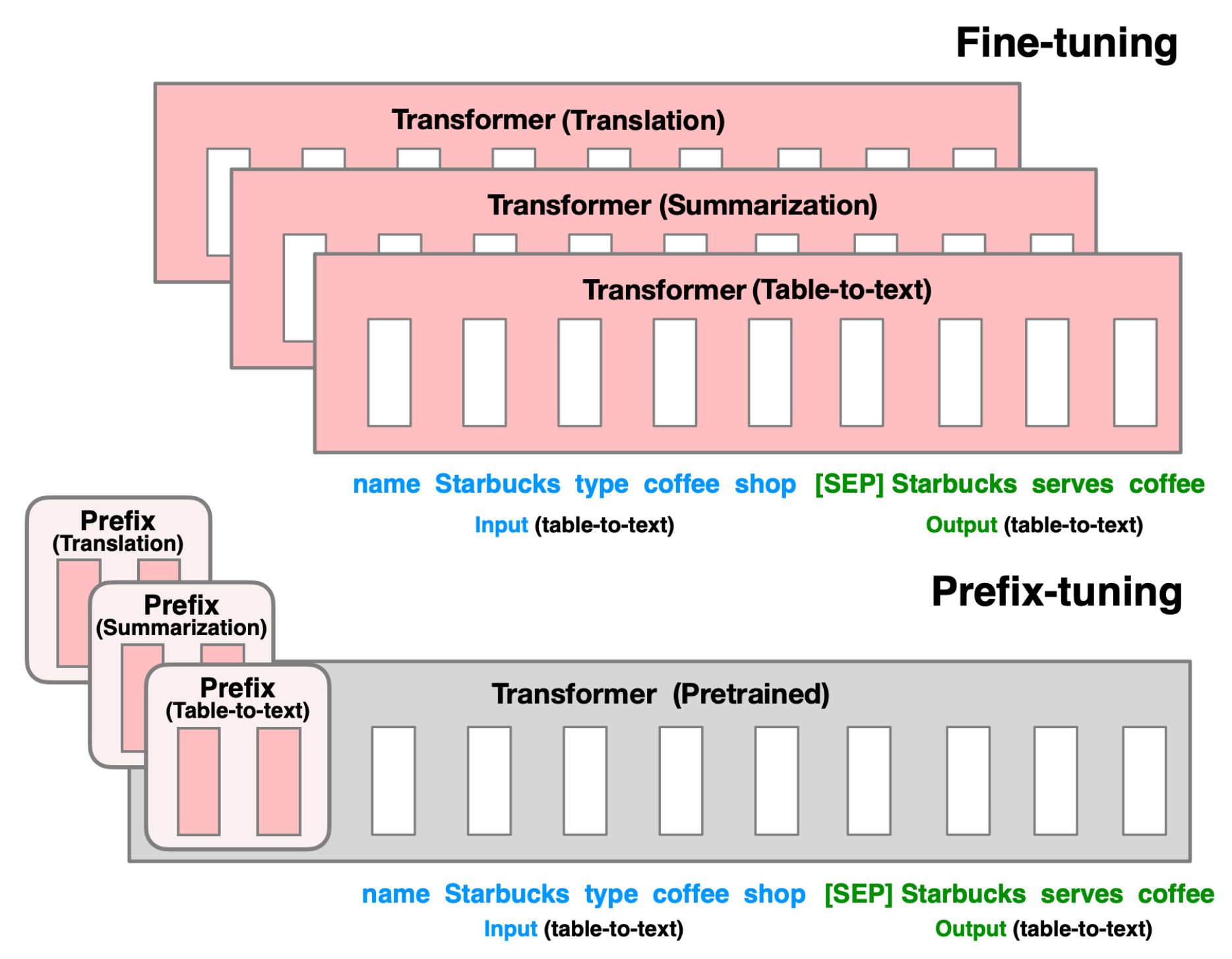
Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 2021.1
Smart prompt design essentially produces efficient context that can lead to desired completion.
- Prefix-Tuning指在输入序列(命名为prefix)的开头指定少量可训练的参数来控制LM, [prefix;x;y]。Let $P_{idx}$ be a set of prefix indices and dim($h_{i}$) be the embedding size. The prefix parameters $P_{\theta}$ has the dimension $|P_{idx}| \times dim(h_{i})$ and the hidden state takes the form:$$
h_{i}=\left\{\begin{array}{ll}
P_{\theta}[i,:], & \text { if } i \in \mathcal{P}_{\text {idx }} \\
\operatorname{LM}_{\phi}\left(z_{i}, h_{<i}\right), & \text { otherwise }
\end{array}\right.
$$ - 注意训练时预训练模型的参数固定:
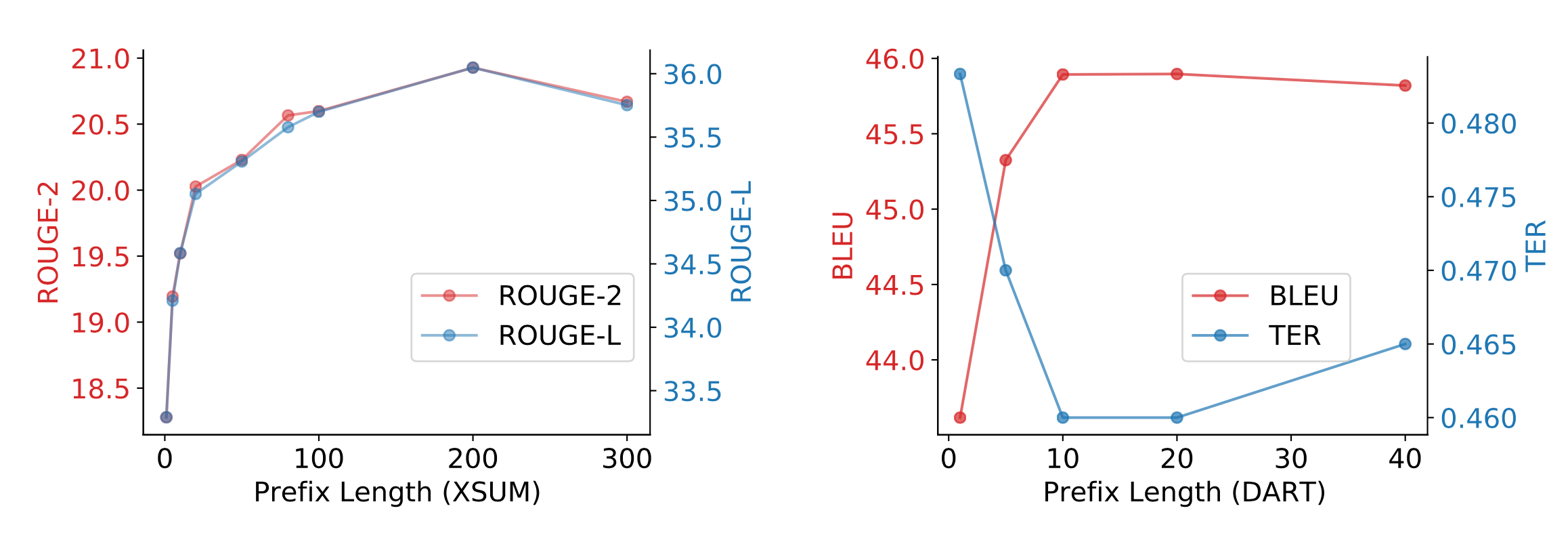
- 实验结果:
- 结论:
Fine-tuned models achieve better task performance but they can fail in the low data regime. Both AutoPrompt and Prefix-Tuning were found to outperform fine-tuning in the regime where the training dataset is small (i.e. 10^2 − 10^3 samples). As an alternative to fine-tuning, prompt design or learning the context embedding is much cheaper. AutoPrompt improves the accuracy for sentiment classification a lot more than manual prompts and achieves similar performance as linear probing. For the NLI task, AutoPrompt obtains higher accuracy than linear probing. It is able to retrieve facts more accurately than manual prompts too. In low data regime, Prefix-Tuning achieves performance comparable with fine-tuning on table-to-text generation and summarization.
P-tuning
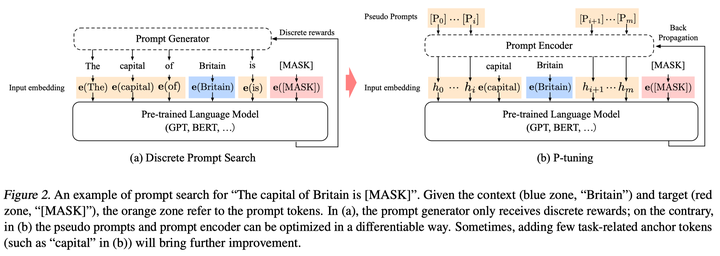
为了(1)保持语义的关联、(2)保持 token 间的上下文依赖关系,作者使用一个可训练 LSTM 模型——即上图(b)中的 Prompt Encoder——生成的 embedding 替换模版中的词。
- 在这一基础上,对某些和任务相关的 token 进行保留(task-related anchors),比将它们也随机训练带来的效果更好。
- 然后在少样本场景,只训练 LSTM(即只进行寻找 prompt);
- 在全量数据场景,全部参数进行 fine-tuning(即寻找 prompt 和 fine-tuning 共同进行)。
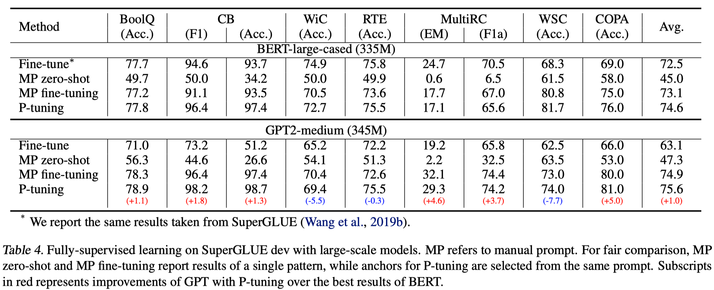
在SuperGLUE上,对比 BERT-large 和 GPT2-medium(和 base 结果类似,这里只贴一个):
Reference
- https://mp.weixin.qq.com/s/w0BH7Uty3In09QIHdVEG8
- https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247512167&idx=1&sn=cc7695d92362e3b18a6e8969fb14dc27&chksm=96ea6fe7a19de6f1be86b965e268df1b9c6320810cf32b6d64ddd3d238bf9088be41fb36adfe&scene=21#wechat_redirect
- https://helicqin.github.io/2021/02/05/Controllable%20Neural%20Text%20Generation/
- https://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247524141&idx=1&sn=d834270cad058931e04392dce844a643&chksm=96ea40ada19dc9bb7f490e9f025b138aa3ed77e66aed544dd310eb6b85bc6018a255f8f4af6b&scene=21#wechat_redirect